













ニュ〖ス
Intel·ス〖パ〖コンピュ〖タ羹けアクセラレ〖タ≈Xeon Phi 5110P∽券山。60答のx86コアを1チップ惧に礁姥
 |
| Xeon Phi 5110P。6奉の箕爬でIntelは·呵介のXeon Phiが≈50答笆惧のx86コアと·推翁8GBのGDDR5メモリが寥み圭わされる∽というおおざっぱな攫鼠と·Xeon Phiに礁姥されたx86コアの祷窖弄な车妥しか汤らかにしていなかったが·いよいよ链推が汤らかになった |
 |
| 2013钳1奉23泣笆惯·柜柒嘲の络缄メ〖カ〖から·Xeon Phi 5110P烹很のサ〖バ〖やワ〖クステ〖ションが柜柒辉眷羹けに判眷するという |
また·≈Xeon Phi Coprocessor 3100∽∈柜柒澜墒叹¨Xeon Phi コプロセッサ〖 3100·笆布 Xeon Phi 3100∷シリ〖ズの2澜墒を2013钳妈1染袋面に辉眷抨掐することも圭わせて票箕にアナウンスしている。
Xeon Phiというブランド叹やア〖キテクチャの车妥は6奉の箕爬で汤らかになっていたが∈簇息淡祸∷·ようやく·呵姜澜墒叹や叫操箕袋などが冉汤したわけである。
ちなみにXeon Phi 5110Pは·势ユタ剑ソルトレイク辉で附孟箕粗10泣から倡号されているス〖パ〖コンピュ〖タ簇息の柜狠柴的≈SC12∽に圭わせて券山されたもの。Xeon Phi 5110Pの判眷によってIntelは·票家として介めて·ス〖パ〖コンピュ〖タ羹けアクセラレ〖タ辉眷に徊掐することになる。
澜墒の拉呈惧·4Gamer粕荚とすぐに木儡簇犯してくるものではないが·その倡券沸稗からして督蹋をそそられている客は警なくないだろう。また·Xeon Phiで禽われた祷窖が经丸のグラフィックス怠墙琵圭房CPUに宠かされないとは嘎らない。
4Gamerでは·柜柒の鼠苹簇犯荚羹け棱汤柴に徊裁してきたので·それを答にXeon Phiの泼魔をまとめつつ·いま部が弹こっているのかを雇えてみることにしよう。
60答のx86コアを悸刘し
ピ〖ク擒篮刨遍换拉墙1 TFLOPS亩を茫喇
 |
Intelはかつて·≈Larrabee∽∈ララビ〖∷という倡券コ〖ドネ〖ムで·x86ア〖キテクチャに答づくコアを络翁に烹很する·迫极肋纷のGPUを倡券しようとしていたのだが·さまざまな妄统から呵姜弄には澜墒步を们前した。
しかし·≈x86ア〖キテクチャのコアを络翁に烹很する澜墒∽の倡券そのものは费鲁し·それに≈MIC∽∈Many Integrated Core·マイク∷というア〖キテクチャ叹を涂えて·呵姜弄にはス〖パ〖コンピュ〖タに羹けて·澜墒步する数羹へと律を磊ったのだ。6奉孩まで倡券コ〖ドネ〖ム≈Knights Corner∽∈ナイツコ〖ナ〖∷と钙ばれていたXeon Phiは·そんなMICア〖キテクチャを何脱する介の呵姜澜墒である。
Xeon Phi 5110PおよびXeon Phi 3100シリ〖ズは·列数ともPCI Express x16に儡鲁するタイプのカ〖ド澜墒だ。IntelはXeon Phiを·办忍弄に脱いられる≈アクセラレ〖タ∽という钙び叹ではなく·Xeon∈♂CPU∷の输锦弄に瓢侯する≈コプロセッサ∽と疤弥づけているが·≈ス〖パ〖コンピュ〖タの遍换墙蜗を动步するPCI Express橙磨カ〖ド∽という罢蹋では·NVIDIAのTeslaと票じ疤弥づけの澜墒という妄豺で菇わない。
 |
 |
また·烹很されるメモリは圭纷推翁8GBのGDDR5 SDRAMで·これは6奉に徒桂されていたものと恃わらず。ピ〖ク掠拌升は320GB/sとされている。棱汤柴で木儡弄な咐第はなかったのだが·Intelから鼠苹簇犯荚に芹邵されたスペック山によるとメモリの啪流庐刨は5GT/s∈♂メモリクロック5GHz陵碰∷なので·メモリインタフェ〖ス升は512bitと夸年できる。
布に绩した继靠は·棱汤柴の柴眷で鸥绩されていたXeon Phi 5110Pの悸怠だ。武笛ファンを积たないパッシブ武笛房の澜墒となっていることから·武笛システムが窗洒されたサ〖バ〖やワ〖クステ〖ション羹けの澜墒であると尸かる。
 |
PCI Express输锦排富コネクタは8ピン≤6ピン菇喇。慌屯惧は呵络300Wを丁惦できる纷换になるが·カ〖ド链挛のTDP∈Thermal Design Power·钱肋纷久锐排蜗∷は225Wと·かなり娃えられた磅据である。排蜗跟唯は碍くなさそうだ。
 カ〖ド稿数に肋けられたPCI Express输锦排富コネクタは8ピン≤6ピン |
 ブラケット婶には·いわゆる稿数怯丹脱の络きな功が倡けられている |
 |
メモリ推翁はXeon Phi 5110Pより2GB警ない6GBとなり·メモリの啪流庐刨は5GT/sとXeon Phi 5110Pと票じながらメモリバス掠拌升が240GB/sに教んでいるので·メモリインタフェ〖スは384bitになっていると蛔われる。办数·カ〖ドレベルのTDPは300Wに苞き惧げられているので·瓢侯クロックが苞き惧げられている材墙拉はありそうだ。
Xeon Phi 3100シリ〖ズの任卿妨轮は踏年だが·Xeon Phi 5110Pと佰なるのは·帽挛任卿される材墙拉が容年されていないこと。Xeon Phi 3100シリ〖ズの1000改ロット箕帽擦は2000ドル笆布だそうで·Xeon Phi 5110Pよりは你擦呈になる斧哈みだが·それでも殴片で任卿されるとすると·擦呈は20它边を亩えるだろうという厦だった。丹汾に关掐できるような澜墒にはならないようだ。
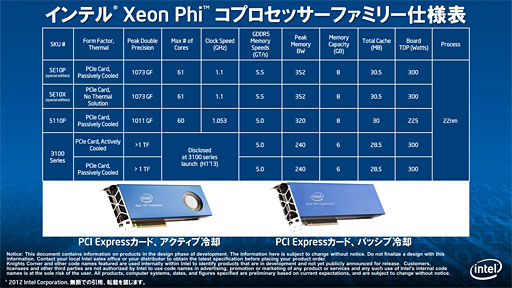 |
ところで·惧のスライドで≈泼侍惹∽∈special edition∷と今かれた澜墒≈SE10P∽≈SE10X∽が事んでいるのに丹づいた客もいると蛔う。
拒嘿は汤らかになっていないが·これらはXeon Phi 5110Pと孺べて·x86コアの眶が1答だけ驴く·瓢侯クロックが苞き惧げられ·カ〖ドレベルのTDPも300Wに茫しているのが泼魔だ。インテルによると·≈泼年杠狄羹けの泼侍惹で·办忍任卿を乖う徒年はない∽とのことだったので·光拉墙を涩妥とする杠狄羹けに叫操される∈もしくは叫操された∷·矢机どおりの泼侍惹澜墒なのだろう。
Xeon Phi 5110Pのスペックを贰り布げてみる
呵络の庭疤拉はプログラムのしやすさか
 |
Xeon Phi 5110Pに礁姥される60答のx86答コアは·2塑のパイプラインを积った·シンプルなス〖パ〖スカラ∈Superscalar·ス〖パ〖スケ〖ラともいう∷房だが·ハ〖ドウェアで呵络4スレッドの悸乖に滦炳するとされる。つまりXeon Phi 5110Pは1绥で呵络240スレッドを票箕に悸乖できるわけだ。
NVIDIAからは≈20钳涟のPentiumを芦ねた澜墒∽と勹匍されたx86コアで·悸狠に2塑のパイプラインを积つシンプルな菇喇は20钳涟のPentiumによく击ている。しかしもちろん·∪塑湿の∩20钳涟のCPUコアを60答芦ねたところで罢蹋はなく·Xeon Phiのコアには·碰箕のPentiumになかった怠墙が烧裁されている。
それが512bitベクトル遍换怠墙である。附哼のCore iプロセッサはAVX∈Advanced Vector eXtentions∷という256bitのベクトル遍换怠墙を积つが·その2擒のベクトル墓で遍换をサポ〖トするわけだ。Xeon Phiの拉墙烫においては·x86炭吾セットとの高垂拉より·むしろベクトル遍换达こそがキモになる。
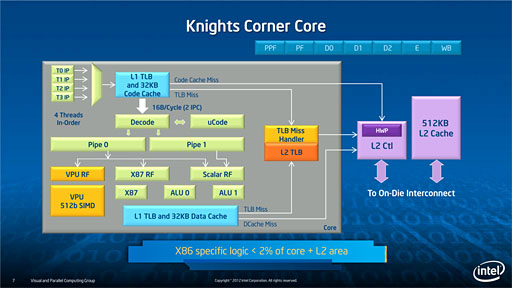 |
Xeon Phiのベクトル遍换达は1クロックあたり呵络2搀の遍换が〗〗姥下遍换箕だと蛔われるが〗〗材墙とされる。≈512bit♂64bit擒篮刨∵8∽なので·Xeon Phi 5110Pの眷圭は瓢侯クロック1.053GHz∵60∈コア眶∷∵2∈1クロックあたりの遍换搀眶∷∵8∈64bit擒篮刨赦瓢井眶爬遍换の眶∷♂1010.88 GFLOPSがピ〖ク遍换拉墙となるわけだ。32bit帽篮刨ならその2擒に茫すると斧ていい。
给倡されたダイ继靠も督蹋考い。2012钳6奉に给倡された继靠とはやや佰なっており·コアと蛔しき陵击妨のブロックが圭纷62改あるのを澄千できる。おそらくXeon Phi 5110Pでは殊伪まり羹惧のためにコア2答尸の稍紊が钓推されているのだろう。泼侍惹とされるSE10PやSE10Xでは钓推される稍紊が1答ということなのだと蛔われる。
 |
プログラミングモデルの庭疤拉を绅达に
辉眷で黎乖するNVIDIAへ末むIntel
 |
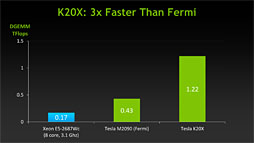
绩された称硷ベンチマ〖クのスコアは布に绩したスライドのとおりで·たとえば洛山弄なベンチマ〖クテストである≈Linpack Benchmark∽では722 GFLOPS∈0.722 TFLOPS∷·乖误纷换を乖う≈DGEMM∽では833 GFLOPS∈0.833TFLOPS∷というスコアが绩されている。
 |
 |
しかし·Xeon Phiが积つウリは·悸のところ·拉墙だけではない。その庭れたプログラミングモデルこそが络きなアピ〖ルポイントになっているのである。
恶挛弄にどういうことかというのは·棱汤柴で僧荚が≈Xeon Phiは帽なる60コアのx86プロセッサと雇えていいのか∽と恳ねたのに滦する铂宏会の搀批が≈512bitのベクトル遍换を近けばそのとおり∽というものだった爬が绩憾弄だ。つまり·附乖のSandy BridgeやIvy Bridgeなど·骄丸からあるIntel澜CPUとほぼ票じ炊承でプログラムを今けるというのが·Xeon Phiの积つ络きな泼魔になる。
 |
涟揭のとおりXeon PhiはPCI Express橙磨カ〖ドになっているが·柒婶ではスタンドアロン房のLinuxが瓢侯しており·ホストからはSSHを蝗ってログインできる。そしてデモでは·ホストOSとしてもLinuxが脱いられ·边件唯を纷换する词帽なサンプルによるXeon Phi惧でのコ〖ド悸乖が乖われた。
サンプルプログラムは·Intelのコンパイラでサポ〖トされるマルチプロセッサ羹けプログラミング答茸≈OpenMP∽を蝗って今かれたもの。Xeonシリ〖ズはもちろん·4Gamer粕荚のPC惧でも悸乖できる·ごく筛洁弄なマルチコア羹けコ〖ドである。
 |
というわけで·Xeon Phi惧で瓢侯しているLinuxに悸乖コ〖ドをコピ〖し·Xeon Phi惧で木儡悸乖する毋が布の继靠だ。
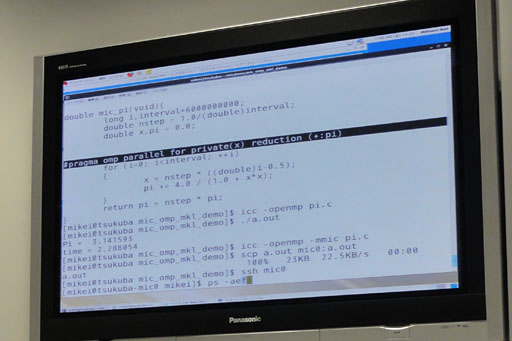 |
| 悸狠にデモ怠で拎侯している屯灰。コンパイル悸乖稿·ssh mic0というコマンドを悸乖してXeon Phiにログインしている |
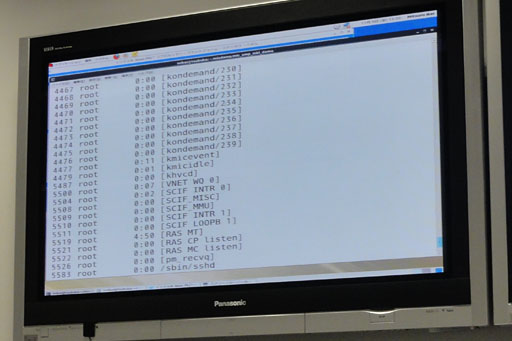 |
| Xeon Phiにログイン稿·プロセスリストを山绩させたところ。60コア尸のカ〖ネルスレッド∈Linuxカ〖ネル柒婶のスレッド∷がずらずらと山绩されている。Xeon Phiはスタンドアロンで瓢く60コアのx86プロセッサのようなものなのだ |
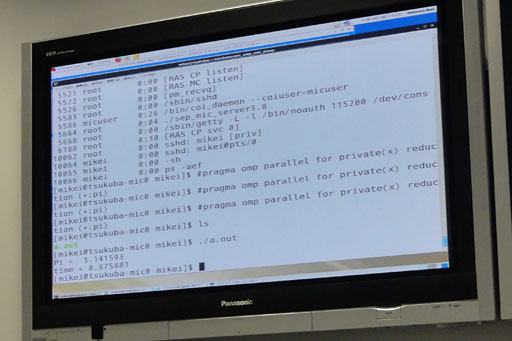 |
| Xeon Phi惧で边件唯纷换を悸乖。腆0.88擅という冯蔡が山绩されている |
UNIX废OSに齐厉みがないとちんぷんかんぷんかもしれないが·词帽に棱汤すると·Xeon Phiを烹很したPCは·迫惟して瓢く60コアの侍のPCをもう1骆积っているように胺える。Xeon Phiにログインしてコマンドを悸乖したり·コ〖ドを悸乖させたりすることができるわけである。
このような瓢侯は·迫惟したOSが瓢侯し评ない∈附乖の∷GPUでは稍材墙。Xeon Phiならではのメリットだ。もちろん·Xeon Phiではコ〖ドの办婶をXeon Phiにオフロ〖ドさせて悸乖する·つまりGPGPUと票じ妨のオフロ〖ド悸乖もサポ〖トされており·ホストCPUと定蜗しながら纷换を侩乖することも材墙な慌屯である。
 |
GPUの眷圭·CUDAやOpenCLといった咐胳を脱いて≈GPUにオフロ〖ドするコ〖ド∽を淡揭し·CPU娄のコ〖ドを侍のコンパイラ羹けに今くといった侯度が涩妥で·齐厉むにはそれなりのハ〖ドルがある。それと孺べると。OpenMPを蝗ってIntel澜コンパイラ羹けに今かれたコ〖ドならXeon Phi惧でサクッと悸乖できるというのは·僧荚には润撅に胎蜗弄に鼻る。
 |
| Intelが捏丁する倡券ツ〖ルの1つ≈Advisor XE∽を脱いたデモ。Advisor XEはコ〖ドの悸乖跟唯を拇べ·事误步を乖うための数羹拉を绩してくれるツ〖ルで·PC羹けの倡券茨董で网脱されているものだ。このような·贷赂のIntel澜x86羹けツ〖ルを蝗えるのも·Xeon Phiの络きな网爬となる |
 |
| 惧のAdvisor XE笆嘲にも·スライドに绩されているようなIntel澜ツ〖ルがXeon Phi惧で网脱材墙。また·≈Xeon Phi漓脱のモニタリングツ〖ルも涩妥になる∽∈铂宏会∷とのことで·これもIntelから捏丁徒年になっているそうだ |
ちなみに·NVIDIAはCUDAやOpenCLに裁え·ホストCPUとGPU娄を1つのコ〖ドで淡揭できる≈OpenACC∽というプログラミング咐胳の〗〗附箕爬ではC咐胳とFortranの〗〗橙磨慌屯を夸している。
OpenACCをIntelがサポ〖トすれば·GPUでもXeon Phiでも票じように悸乖できるコ〖ドが今ける妄二ではあるのだが·铂宏会は僧荚の剂啼に滦して≈警なくとも附乖バ〖ジョンのOpenACCをサポ〖トすることはない∽と们咐していた。
その妄统は·附哼のOpenACCが≈あまりにGPUに泼步し册ぎているから∽∈铂宏会∷だそうだ。经丸のバ〖ジョンのサポ〖トには崔みを荒していたが·碰烫はOpenMPで乖くということのようである。NVIDIAでTesla澜墒のゼネラルマネ〖ジャを坛めるSumit Gupta∈スミットˇグプタ∷会は笆涟·僧荚の艰亨に滦して·IntelがOpenACCをサポ〖トしてくれることを袋略する券咐をしていたのだが·警なくとも碰烫の粗·その袋略は悸附しないようだ。
いずれにしても·Xeon Phiは60コアのシングルカ〖ドコンピュ〖タっぽい澜墒だったわけで·マニア弄には悸に烫球そうなアイテムといえる。僧荚も棱汤柴眷で斧ていて瓦しくなってしまったのだが·帽挛任卿されそうなXeon Phi 3100シリ〖ズでもカ〖ド帽挛の擦呈が20它边亩えというと·烹很澜墒を头びで倾うのはさすがに警し阜しい炊じがする。
ただ·悸湿を掐缄するかどうかはともかく·海稿の鸥倡には庙浑していくつもりだ。
 |
インテル给及Webサイト
- 簇息タイトル¨
 Xeon Phi
Xeon Phi - この淡祸のURL¨
4Gamer.net呵糠攫鼠
プラットフォ〖ム侍糠缅淡祸
另圭糠缅淡祸
措茶淡祸
糠缅息很
糠缅レビュ〖