












ニュース
西川善司の3DGE:GeForce RTX 50シリーズには,「GeForce RTX 5090」よりも上位モデルが存在する? スペックの謎を解明してみた
 |
本稿では,4Gamer読者が最も注目しているであろう新GeForceの話題を,筆者の解説を交えてお届けしたい。
関連記事


NVIDIA,次世代GPU「GeForce RTX 50」シリーズを発表。前世代最上位モデルの性能を「GeForce RTX 5070」で実現
米国時間2025年1月6日,NVIDIAは,「Blackwell」アーキテクチャを採用する次世代GPU「GeForce RTX 50」シリーズを発表した。デスクトップPC向けGPUは,「GeForce RTX 5090」「GeForce RTX 5080」「GeForce RTX 5070 Ti」「GeForce RTX 5070」の4製品をラインナップしている。
GeForce RTX 5090は105 TFLOPS。125 TFLOPSの上位モデルが存在する可能性
Huang氏が,まず示したのは,「Blackwell」のスペックだ。これは開発コードネーム「GB202」として開発されていた「GeForce RTX 50」シリーズの最上位モデル「GeForce RTX 5090」に相当する。
基調講演ではGB202以外にも,その下位モデルとなる「GB203」「GB205」を採用したGeForce RTX 50シリーズも発表となった。
 |
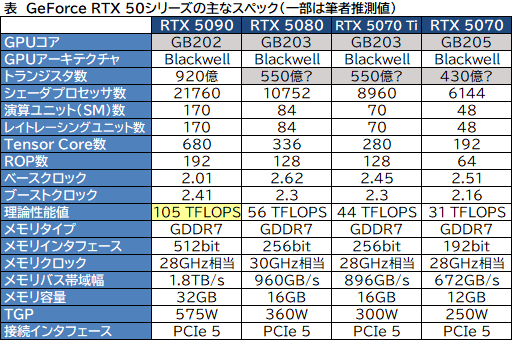
基調講演の直後,NVIDIAの公式WebサイトにGeForce RTX 50シリーズの詳細なスペックが掲載された。詳しく知りたい人は,そちらを参照してほしいが,筆者の推測値も交えた簡易スペック表を示そう。
 |
アーキテクチャ名であるBlackwellの由来は,確率論やゲーム理論などで大きな実績を上げた統計学者兼数学者のDavid Blackwell氏にある。
開発コードネームBlackwellとして知られるGPUは,2024年3月に行われた「GTC 2024」で発表となったサーバー向けGPU「B100」(開発コードネーム GB100)が最初の製品だ。今回発表となったGeForce RTX 50は,その一般消費者向けという位置づけになる。
BlackwellのGB202は,総トランジスタ数が約920億個であると,NVIDIAは明らかにしている。「GeForce RTX 4090」が約763億個だったので,20%ほど増えたわけだ。
なお,製造プロセスについては,基調講演では触れていない。しかし,GB100がTSMCの改良型5nmプロセス「4NP」だったので,GB202も同系になる可能性は高い。TSMCには,同じ改良型5nmとされる「N4」系も存在するので,こちらの可能性もあるにはある。ただ,N4系は汎用プロセスなのに対して,4N系はNVIDIA用カスタムプロセスとして作られたので,その発展形である4NPを採用していると見るのが自然だろう。
出せば売れるので価格を青天井にできるGB100ですら,4NPに踏みとどまったので,製造コストを考えると3nmプロセスに進んだ可能性は低いと見るが,はたしてどうだろうか?
話を戻すと,GeForce RTX 5090のCUDA Core(シェーダプロセッサ)総数は21760基で,GeForce RTX 4090の16384基から33%増えた。GeForce RTX 4090が登場したときは,「GeForce RTX 3090」から56%増えていたので,それに比べると控えめに見える。ただ,GeForce RTX 4090の例は,製造プロセスの大きな変更(※8nmから5nmになった)があったことが大きい。
基調講演では,GB202の理論性能値が「125 TFLOPS」となっていたが,基調講演後に公開されたNVIDIAのスペック情報から計算してみると,105 TFLOPSとなり数値が合わない。
ここで注目すべきは,「Streaming Multiprocessor」(以下,SM)の170基と,レイトレーシングユニット(以下,RT Core)数の170,Tensor Core数の680,そしてROP数の192である。GeForce RTXシリーズになってからのNVIDIA製GPUは,RT Core,Tensor Core,ROPなどの値が,SM数の整数比になっていない場合,そのGPUはSMをいくつか無効化している可能性が高い。つまり,そのGPU自体は,もっと多くのSMを有していることになり,理屈ではすべてのSMを有効化したフルスペック版のGPUを製品化することも可能であると推測できるのだ。
 |
では,フルスペック版GB202はどんな姿なのか。ここでヒントになるのはROP数の192だ。RTXシリーズの特徴から推測するに,フルスペック版のGB202は,ROP数と同じ192基のSMが存在することを推測できる。
GB202のフルスペック版はSM数が192基であると仮定した場合,SM数を128倍すると(※SM 1基あたりCUDA Core数は128基),GB202のフルスペック状態は,CUDA Core数が24576基と計算できる。
そこで,GeForce RTX 5090のブーストクロックの2.41GHzを用いて理論性能値を計算してみると,以下のようになる。
- 24576基×積和算(2 FLOPS)×2.41GHz(ブーストクロック)≒118 TFLOPS
これでも,基調講演でアピールされたGB202の理論性能値である125 TFLOPSには届かない。
そこで,125 TFLOPSを実現するブーストクロックを逆算してみると,2.54GHzとなる。GeForce RTX 4090のブーストクロックが2.52GHzであることを考えると,とくに無謀なクロックでもない。おそらくだが,消費電力の上限縛りなしで,さらに強力な冷却機構を組み合わせたワークステーション版がいずれ登場するなら,このスペックに近いものになるだろう。
ちなみに,前世代最上位の「AD102」は,フルスペック仕様のCUDA Core数が18432基だが,それがGeForce RTX 4090になると,CUDA Core数は16384基だった。のちにAD102の上位モデルとして,ワークステーション向けの「RTX 6000」が登場している。しかし,RTX 6000においてもCUDA Core数は18176基で,2基のSMが無効化されていた。つまり,2025年1月時点で,AD102のフルスペック版の製品は存在しないわけだ。
はたして,125 TFLOPSをフルに発揮できるフルスペック版GB202は製品化されるだろうか。
GDDR7の512bitインタフェースで,メモリモンスターとなったRTX 50
GeForce RTX 50の発表におけるもうひとつのトピックは,なんといってもメモリバス帯域幅だろう。
GeForce RTX 5090のメモリバス帯域幅は,広帯域が売りのHBM2採用GPUを凌駕して,HBM3採用GPUに迫る1.8TB/sに達した。これは,GeForce RTX 4090(1008GB/s)の1.8倍に相当するもので,PlayStation 5 Pro(576GB/s)と比較すれば3倍以上にもなる。
余談だが,PS5 Proの名誉のために述べると,PS5 Proもメモリバス帯域幅の576GB/sを誇るメモリモンスターだ。現行のRadeon製品では,PS5 Proのメモリバス帯域幅を超えるものは多くない。つまりGeForce RTX 5090は,そんなメモリモンスターをさらに超えたモンスターGPUなのだ。
 |
メモリモンスターを実現したもう一方の立役者は,新採用の「GDDR7」メモリだろう。GDDR7は,新世代のグラフィックス用高速メモリで,既存の「GDDR6X」よりも33%ほど高いクロックで動作できる特徴を持つ。つまり,
- メモリバス幅 1.33倍×メモリクロック 1.33倍≒1.8倍のメモリバス帯域幅
という計算になるのだ。
なお,本稿執筆時点では,最大32GHz相当のメモリクロックで動作する製品も存在する。
メモリ性能向上に期待できるのは,まずシンプルに,4Kなどの高解像度グラフィックスにおけるレンダリングの高速化だろう。だが,それ以上に期待したいのは,レイトレーシングの劇的な性能向上だ。レイトレーシングというキーワードから,演算負荷を連想する人が多いが,むしろ,現状のレイトレーシング技術におけるボトルネックは,メモリバス帯域幅にあるのだ。
レイトレーシングを簡単に言うと,「光源が放ったレイと,3Dシーン内のポリゴンとの衝突判定」である。実際の処理としては,3Dシーンをレイトレーシング向けに表現した「Bounding Volume Hierarchy」(BVH)構造体に対するデータ探索に相当する。レイの推進とポリゴンとの交差(衝突)判定は,事実上,超ランダムなメモリアクセスなのだ。
現在のレイトレーシング対応GPUでは,この高速化のために,キャッシュメモリ増量やアクセス効率向上などの工夫を凝らしているが,根本的な解決は,メモリバス帯域幅の向上となる。つまりGeForce RTX 5090では,レイトレーシングが笑えるほど高速化されるはずである。
もちろん,それでも究極のゴールである「ゲームグラフィックス要素を全レイトレーシング化」までには,まだ全然性能は足りないわけだが。
 |
そのほかにもメモリバス帯域幅向上は,近代ゲームグラフィックスの標準技術である「物理ベースレンダリング」(Physically Based Rendering,PBR)を支える多段テクスチャ読み出しの高速化にも貢献するだろう。
AIベースの超解像技術である「DLSS」系も,メモリバス帯域幅を大量に消費するモンスターの一種なので,メモリバス帯域幅向上はとてもありがたい利点となっているはずだ。
CUDA Coreがニューラルグラフィックス対応へ
レイトレーシングとは別の「次世代ゲームグラフィックス技術」として台頭しつつあるのが「ニューラルグラフィックス」という概念だ。
大雑把に説明すると,ニューラルグラフィックスとは,「ピクセル単位のライティング,シェーディング演算って,ゲームグラフィックス用途ならば,まじめに計算しなくてもよくね? なんならAIに推論させてもバレないんじゃね?」という発想にもとづく技術である。
ゲームグラフィックスは,もう何十年も前から「説得力が高ければ,正確さは問わない」という文化で発展してきたのはご承知のとおり。たとえば,現在主流であるデプスシャドウ技術ベースの,さまざまなソフトシャドウ技術も,レイトレーシングで描画したものと比較すれば,光学的にも物理的にも正確ではない。しかしプレイヤーの目には,十分に自然な影と認識されている。
実際に描画した低解像度の映像を,高解像度に超解像処理するDLSSなどの技術も,広義的にはニューラルグラフィックスの一種だと言えよう。
 |
というわけで,NVIDIAはニューラルグラフィックスの概念を,ピクセル単位のライティングやシェーディングにも適用する方針を明らかにした。
具体的な実装方法については未公表なので,今後の発表に期待という状況だ。筆者が推測するに,
- 注目しているピクセルの3D空間上における座標とその向き(法線ベクトル)
- 光の位置と向き(光源ベクトル)
- 視点の位置とその向き(視線ベクトル)
- 面の粗さ(ラフネス)
- 金属性(光の波長に対する影響度)
- 拡散反射率(ディフューズ)
- 鏡面反射率(スペキュラ)
といった複数のパラメータを引数として,事前に用意した各材質ごとの「反射特性学習データ」をテクスチャ化したデータを,あらかじめ定義したニューラルネットワークによる推論アクセラレータにかけて,ライティングとシェーディングを推論ベースで算出させる,というアプローチになるのではなかろうか。
この手法のメリットは,通常の物理ベースレンダリングでは,人肌や半透明材質における表面下散乱現象や,多層レイヤーで処理しなければならなかった複雑な物理レンダリング,これまでは光の波長レベルのシミュレーションが必要だった「スペクトラルレンダリング」を,まじめに計算するよりもだいぶ高速に実現できる点にある。
あえて脱線するが,「まじめに計算するよりもAIのほうが正確性が高い」(ことがある)と,似たようなパラダイムシフトが気象予測の世界にも起きている。たとえば,気象予測の世界では,「気温,湿度,風速,風向き,地形,海流」といった多元的パラメータを用いてまじめに計算しても,なんらかの不確定要因が邪魔をして,正確さに難が出てしまうことがある。そこで,気象パラメータと過去の気象の観測結果をAIに学習させて得た学習データを元に,気象パラメータを引数にして,生成AI的に予測させるという手法が台頭している。不確定要因の影響を,AIによってある程度低減させる効果を期待しているわけだ。
 |
ゲームグラフィックスにおいても同様で,少ないパラメータでまじめに計算しても,どうしてもリアルにならない材質表現のライティングやシェーディングは,AIに補助してもらいながら計算してしまおうというわけである。
今回の基調講演でHuang氏は,「Blackwellでは,プログラマブルシェーダユニットが浮動小数点演算と整数演算を同時にできる。そしてプログラマブルシェーダユニット自体が,ニューラルネットワークを取り扱えるようになった」と述べている。つまりBlackwellでは,浮動小数点対応の通常のプログラマブルシェーダユニットと並行動作できる整数特化型のプログラマブルシェーダユニットが,行列演算型に拡張されてニューラルネットワークに対応したということになる。
Huang氏は「この新しいシェーダ技術をニューラルシェーダと呼ぶ」とも説明していた。ニューラルネットワークベースのニューラルシェーダは,先述した整数ベースのプログラマブルシェーダユニットで動作させるのであろう。
Huang氏はこれ以外にも,「ニューラルテクスチャコンプレッション」と「ニューラルマテリアルシェーディング」というキーワードを掲げ,「これらが利用できるのはBlackwellだけ」と強くアピールしていた。これら,2つの新しいキーワードは,ニューラルシェーダの概念そのもののだと思われる。
多段で物理ベースレンダリングを行う場合,複数のPBRテクスチャが必要だ。ニューラルシェーダの概念ならば,単一の学習データをテクスチャとして表現できてしまうので,これはニューラルテクスチャコンプレッションと言えよう。また,多様なパラメータを用いて推論ベースでライティングやシェーディングすることは,ニューラルマテリアルシェーディングと同じ意味になる。
興味深い技術だが,気になるのは並列動作できる整数プログラマブルシェーダユニットを駆動させるための命令セットは,新しいものが必要なのかどうかだ。もちろん,従来のシェーダ言語でも,整数ベクトルや整数行列の演算は行えるが,高速に動かすのなら,専用の命令体系があったほうがいい。
ちなみに,PS5 Pro専用の超解像技術「PSSR」では,8bit整数ベースで「3x3」のAIカーネルを超高速に動作させるために,AMDに依頼して,わざわざその推論アクセラレータに専用の整数SIMD演算ユニットを搭載した。さらに,これらを駆動するための命令セットも新設している。
GeForce RTX 5070はGeForce RTX 4090並みの性能というのは本当か?
Huang氏は,GeForce RTX 50シリーズの価格について,「GeForce RTX 4090相当の性能を持つGeForce RTX 5070は,価格が3分の1になる」と,価格対性能比の高さをアピールしていた。
 |
 |
とはいえ,このアピールはやや盛り過ぎ。GeForce RTX 5070は,理論性能値もメモリバス帯域幅も,GeForce RTX 4090にはまったく及ばない。新しいDLSS技術の「DLSS 4」を活用すれば,「GeForce RTX 4090に近い性能が出る」と理解したほうがいいだろう。
筆者は,「GeForce RTX 5070 Ti」が,価格対性能比面で台風の目になりそうだと感じる。逆に,位置付け的には「GeForce RTX 5080」が微妙な感じだ。
また,同時に発表となったノートPC向けGeForce RTX 50シリーズを搭載したノートPC製品の想定売価も明らかになった。ノートPC向けGPUは,同じGeForce RTXでも,デスクトップPC向けGPUの1ランク下のチップを採用する点には注意してほしい。たとえばノートPC向けのGeForce RTX 5090は,デスクトップPC向けGeForce RTX 5080のチップを使っているという具合だ。
 |
Blackwellアーキテクチャでは,レイトレーシングユニット関連の機能も拡張されているはずだが,時間と誌面の都合もあり,続報は次回にしたい。
NVIDIAのGeForce RTX 50製品情報ページ
- 関連タイトル:GeForce RTX 50
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー