












ニュース
西川善司の3DGE:GeForce RTX 50完全解説前編:Blackwell世代の構造とレイトレーシングにおける革新
 |
先代アーキテクチャの名称(および開発コードネーム)は「Ada Lovelace」(エイダ・ラブレス,以下 Ada)。一方,GeForce RTX 50シリーズのアーキテクチャ名は,「Blackwell」(ブラックウェル)となった。Blackwellとは,確率論やゲーム理論などで大きな実績を上げた統計学者兼数学者のDavid Blackwell氏にちなんだ命名だ。
余談だが,GeForce RTX 30シリーズの「Ampere」(アンペア)以前は,物理学者からの引用が多かったが,ここ2世代はソフトウェア寄りの学者からの引用となっているのが興味深い。
Blackwellのお披露目となったNVIDIAのCEOであるJensen Huang(ジェンスン・ファン)氏によるCES 2025基調講演を踏まえての第1報は,すでに掲載済みだ。ただ,この時点では,あくまでも基調講演で明らかになったことしか情報がなかった。その後,NVIDIAによって,Blackwellに関するかなり深いレベルでの情報開示が行われたので,本稿では,追加情報を踏まえ,改めてGeForce RTX 50シリーズの全貌に迫ってみよう。
なお,非常に膨大かつ多岐に渡る内容であるため,前後編に分けて解説する予定だ。
RTX 5090のGPU「GB202」の全貌
まずは,発表となった各GPUのスペックから見ていこう。
Blackwellの第一報時点では,筆者の推測や概算で埋めていたGeForce RTX 50シリーズのスペック表だったが,より詳細まで開示された資料をもとに作り直した(表1)。この表では,NVIDIAが公開した初期資料にあった誤記部分も訂正してある。
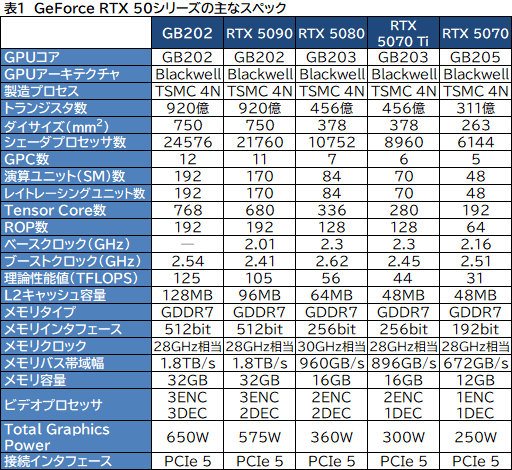 |
「GeForce RTX 5090」(以下,RTX 5090)として登場する,現時点で最上位GPUが「GB202」だ。表内では,製品としては存在しないフルスペック版GB202の仕様も示している。
第一報でも触れたとおり,RTX 5090は,GB202のフルスペック状態からシェーダプロセッサ(CUDA Core)を2816基分も無効化したものだ。第一報時点で筆者は,GB202を「先代AD102の基本設計を,そのまま継承したものだろう」と考えていたが,そうではなかった。
筆者は,先代のAD102のように,GPUコアに相当するミニGPUクラスタである「Graphics Processor Cluster」(以下,GPC)の数を12基から16基に増やす一方で,GPUが内包する「Streaming Multiprocessor」(以下,SM)数は12基に据え置いた構造になっているのではないかと考察していたのだ。しかし,実際のGB202は,GPCの数をAD102と同じ12基としつつ,GPC内にあるSMの数を,12基から16基へと増量したのだ。
次のスライドが,フルスペック版GB202のブロック図となる。
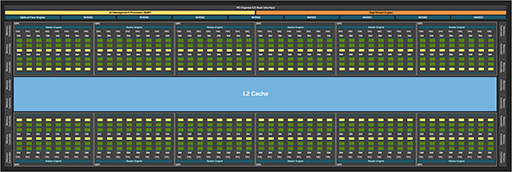 |
GPCは据え置いてSM数を増やすという設計方針は,AMDがRadeon RX 6000シリーズの「RDNA 2」から,Radeon RX 7000シリーズの「RDNA 3」へと移行したときに,CU数を増やさずSIMD32演算器を増量した設計思想と酷似している。つまり,RDNA 3と同じく,GB202も並列度の向上よりも,実行効率の向上を狙った設計方針を採用したと言えよう。
そういうわけで,フルスペック版GB202のCUDA Core数はこうなる。
- 128 CUDA Core×16 SM×12 GPC=24576 CUDA Core
一方で,製品化されたRTX 5090は,GPCが11基に減っており,CUDA Core総数は21760基ということなので,SM 16基のGPCが8基と,SM 14基のGPCが3基という内訳になる。
- 128 CUDA Core×16 SM×8 GPC+128 CUDA Core×14 SM×3 GPC=21760 CUDA Core
これをベースに,筆者が独自に作成したRTX 5090のブロック図を示そう。下段に並ぶ3つのGPCはSM 14基構成だが,それ以外の8つのGPCはSM 16基構成だ。右下の空きは,GPCが1基減っているためである
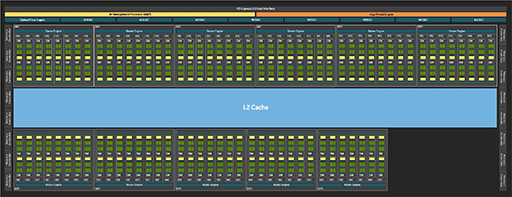 |
ちなみにNVIDIAは,当初公開した資料で,GB202のブロック図として次の少しいびつな図を示したが,すぐに引っ込められた。興味深いので,あえて載せておこう。
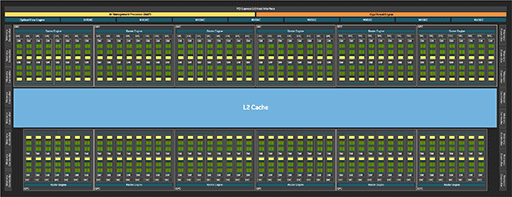 |
この図はGPC 12基構成なのだが,そのうち2基は,SMが14基に減っている。CUDA Core総数は24064基だ。これは,かなりの高確率で,後に出てくるであろうGB202のワークステーション向けモデルだと,筆者は考えている。その根拠は,GPCとSMの構成の違いが,「GeForce RTX 4090」とワークステーション向けGPU「RTX 6000 Ada」の違いに酷似しているからだ。
予想だが,謎のブロック図のもとになったワークステーション版GB202は,2025年8月中旬に開催予定のコンピュータグラフィックス学会「SIGGRAPH 2025」のタイミングで発表されることだろう。GeForce RTX 4090とRTX 6000Adaの例にならうなら,ワークステーション版GB202は,容量が2倍となる64GBのGDDR7メモリを搭載して,価格はRTX 5090の4倍近くとなるのではなかろうか。
GeForce RTX 5080/5070 Ti/5070の構成を考察する
続いては,「GeForce RTX 5080」(以下,RTX 5080)や「GeForce RTX 5070 Ti」(以下,RTX 5070 Ti)で使われている「GB203」や,「GeForce RTX 5070」(以下,RTX 5070)の「GB205」についても考察していく。
 |
NVIDIAに問い合わせたところ,GPC 1基あたりのSM数が16基という設計は,GB202のみとのこと。具体的には,RTX 5080/RTX 5070 TiのGPUであるGB203では,Ada世代と同じくGPC 1基あたりのSM数が12基,GB205ではGPC 1基あたりのSM数は10基となっている。GPC数は表にあるとおり,順に7基,6基,5基が正しい。
これをもとに,RTX 5080とRTX 5070 Tiの構成を考察しよう。RTX 5080のCUDA Core数は10752基で,GPCが7基ということは,計算式はこうなる。
- 128 CUDA Core×12 SM×7 GPC=10752 CUDA Core
同様に,RTX 5070 TiのCUDA Core数は8960基だ。
- 128 CUDA Core×12 SM×4 GPC+128 CUDA Core×11 SM×2 GPC=8960 CUDA Core
RTX 5070 Tiでは,GPC 2基においてSMが1基ずつ(計2基分)無効化してある計算になる。
一方で,GB205ベースのRTX 5070は,CUDA Core総数が6144基で,GPC 5基とのことだから,計算するとこうだ。
- 128 CUDA Core×10 SM×4 GPC+128 CUDA Core×8 SM×1 GPC=6144 CUDA Core
RTX 5070でも,GPCのうち1基から,SM 2基が無効化になっているのが分かる。
2025年以降,これらGPUの上位モデルとして「SUPER」モデルが登場することがあった場合,現時点ではで無効化されているSMが,有効化されることがあるかもしれない。
製造プロセスとダイサイズ,トランジスタ数
GeForce RTX 50シリーズのGPUである「GB20x」シリーズは,すべてが,TSMCの4Nプロセスで製造されている。つまり,Ada世代のGeForce RTX 40シリーズとは同じ製造プロセスで,「4NP」の採用は見送られた。
GeForce RTX 40シリーズの解説記事を執筆した当時,筆者は,TSMC 4Nを4nm相当と記したところ,後日訂正することになった。しかし,今回提供されたNVIDIAの資料によると,GeForce RTX 40/50シリーズはどちらも「TSMC 4nm 4N NVIDIA Custom Process」であると明記されていたのだ。TSMCの4Nも4NPも,基本的に5nmプロセスのマイナーチェンジではあるのだが,TSMCかNVIDIAの定義に,変更があったのかもしれない。とにかく,GeForce RTX 50シリーズの製造プロセスは,TSMC 4Nの4nmプロセスであり,GeForce RTX 40シリーズと同じであるとNVIDIAが主張しているので,本稿でもそう記述しておく。
さて,ウルトラハイエンドエンド市場向けであるRTX 4090(AD102)とRTX 5090(GB202)を比較すると,トランジスタ数は約763億個から約922億個へと約21%ほど増大した。
 |
Samsung Semiconductorの8nmプロセスを用いた「GeForce RTX 3090」(GA102)から,TSMC 4NプロセスのRTX 4090(AD02)へ変わったときは,約283億個(GA102)から763億個(AD102)へと約2.7倍も増大したのに比べると,GB202での増加率は,かなり控えめ。製造プロセスが大きく変わっていないのだから,それも無理はないことだ。
 |
製造プロセスを変えずに,20%強のトランジスタ数増とダイサイズ増は素晴らしいが,一方で動作クロックは,ほとんど向上していない。
また,トランジスタ数の増加に合わせて,消費電力も約28%ほど増えている。「Total Graphics Power」(TGP,TDPに等しい)は,RTX 4090の450Wから,RTX 5090では575Wまで上昇してしまった。NVIDIAは,RTX 4090の推奨電源ユニットを出力850Wとしていたが,これがRTX 5090では1000Wに引き上げられた。
同じ理由で,RTX 5080の推奨電源ユニットも出力850Wとなり,RTX 4080の750Wより引き上げられている。GeForce RTX 5070 Ti以下では,据え置かれたようだが,いずれにせよ,グラフィックスカードをGeForce RTX 50シリーズ搭載品にアップグレードするときは,電源ユニットの出力強化についても考慮すべきだ。
BlackwellのSMとTensor Core
半導体製品として見れば,マイナーチェンジに見えなくもないBlackwellだが,アーキテクチャに着目すると,全方位で劇的に進化している。アーキテクチャ面の進化について見ていくことにしたい。
Blackwellでは,GPC 1基あたりのSM数が,これまでの12基から16基に増えたのは先述のとおり。しかし,SM内に実装する演算器のCUDA Core数は,これまでと同じ128基のままだ。NVIDIA製GPUにおけるGPC,SM,CUDA Core数の関係を,表2にまとめてみた。
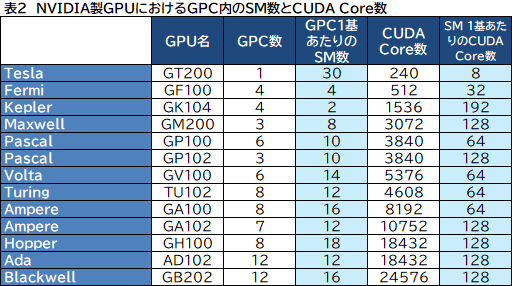 |
SM 1基あたりCUDA Core数が128基という構成は,ここ数世代変わっていないものの,Blackwellでは,CUDA Coreの中身が進化している。次の画像は,NVIDIAがAda世代とBlackwell世代のSMを比較したものだ。
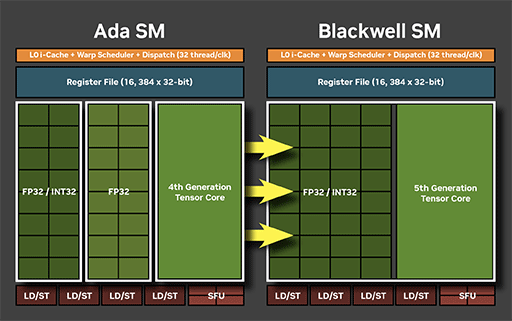 |
Ada世代のCUDA Coreは,32bit浮動小数点数(FP32)演算専用のCUDA Coreと,FP32および32bit整数(INT32)演算兼用のCUDA Coreによる混成となっていた。それがBlackwellでは,すべてのCUDA CoreがFP32/INT32兼用に変わったわけだ。
つまり,BlackwellにおけるSM内のすべてCUDA Coreは,処理対象となるデータスレッドに応じて,FP32演算,あるいはINT32演算のどちらかを処理できる。各CUDA Coreが,FP32演算とINT32演算を同時に行えるわけではないが,必要に応じてどちらにも可能なコンバーチブル(Convertible)仕様になったということだ。
分かりやすく言えば,Ada世代は,FP32演算に重きを置いた設計だったが,Blackwell世代では,オールラウンドタイプに進化したということになる。
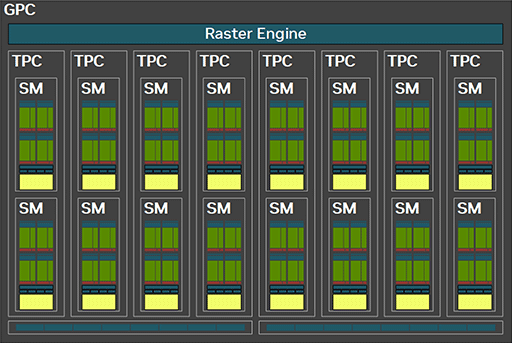
SM内には,32bit×16384本を4セット,総容量にして256KBのレジスタファイルがあり,容量128KBのL1キャッシュ兼用共有メモリがある構成は,Ada世代と変更なし。
 |
 |
数値表現形式の分野は,AI技術と足並みを揃えて進化スピードが速いので,本稿でも軽く解説しておこう。浮動小数点数の表現形式は,符号(正負)ビット,指数項ビット,仮数項ビットの3要素で表される。広く知られるFP32は,符号 1bit,指数項 8bit,仮数項 23bitの合計32bitで表現している浮動小数点数だ。
Blackwellが新しく対応した表現形式は3種類ある。ひとつめは,「Block FP16」だ。「Ryzen AI 300」の解説記事で詳しく触れているが,ここでも簡単に説明しよう。
Block FP16とは,複数の16bit浮動小数点数を1ブロックとして取り扱い,そのブロックを構成するすべての浮動小数点数で,共通の指数項を表現する形式だ。
通常の16bit浮動小数点数(FP16)との違いはこうなる。
- FP16:符号 1bit,指数項 5bit,仮数項 10bit
- Block FP16:符号 1bit,共通指数項 8bit,仮数項 7bit
Block FP16では,値のダイナミックレンジ(※表現できる値の範囲)を左右する共通指数項を,8bitと大きく取って外に追い出し,各値を符号 1bitと仮数項 7bitの合計8bitで表現する。これにより,FP16よりもダイナミックレンジを大きく取りながら,データ量を8bit+α程度にまで削減できる理屈だ。AI処理向けのFP16形式というイメージでいい。
2つめの新表現形式は,生成系AIで採用事例が増えている「4bit浮動小数点数」(FP4)にも対応した。内訳は符号 1bit,指数項 2bit,仮数項 1bitの計4bitで,表現できる数値の範囲は以下のようになる。
- 正の数:+0.5〜+6.0
- 負の数:−6.0〜−0.5
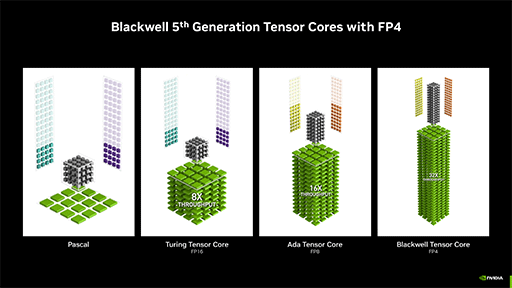 |
狭いと思うかもしれないが,AIの学習対象によっては,記録する値の表現幅はこれで十分の場合も多いという。また,初期学習フェーズではFP16を使っても,最終的な製品AIに載せる正規化済みの学習データは,FP4精度で十分となることが多いそうだ。FP4であれば,データサイズやバス帯域幅の消費はFP16時の4分の1で済む。NVIDIAは,BlackwellのTensor CoreでFP4をネイティブ処理できるように設計したので,演算速度はFP16時の4倍に達するという。
それなら,Ada世代の4×4で16倍の性能をBlackwellが達成できるかというと,メモリアクセス遅延などもあるため,そこまでは行かない。NVIDIAの発表によれば,Black Forest Labs※の画像生成AIモデル「FLUX.1」を30イテレーション※※で動作させると,RTX 4090を使ったFP16ベースで15秒かかっていた生成時間が,Blackwellでは5秒にまで短縮できたそうだ。学習データのサイズも,FP16ベースでは約23GBだったものが,FP4形式を導入すると10GB未満になったという。処理時間や学習データサイズが4分の1にならないのは,すべてのデータをFP4化できないためだ。とはいえ,かなりの性能向上と言えよう。
※ 画像生成AI「Stable Diffusion」の開発者たちが設立した企業
※※ ディフュージョンモデルにおける画像生成プロセスの施行段数
Blackwellで加わった3つめの表現形式は,6bit浮動小数点数(FP6)だ。フォーマットは2種類ある。
- 符号 1bit,指数項 2bit,仮数項 3bit
- 符号 1bit,指数項 3bit,仮数項 2bit
指数項と仮数項の違いにより,上は低ダイナミックレンジで精度重視型の「E2M3」(Exponent 2,Mantissa 3)型,下は高ダイナミックレンジで精度低めの「E3M2」(Exponent 3,Mantissa 2)型と呼ぶ。それぞれの数値表現範囲は以下のとおり。
●E2M3型
- 正の数:+0.125〜+7.5
- 負の数:−7.5〜−0.125
●E3M2型
- 正の数:+0.0625〜+28.0
- 負の数:−28〜−0.0625
E2M3型とE3M2型は,Ada世代のTransformerエンジンから対応し始めたFP8と同様に,演算の過程で適宜変換していく。また,BlackwellのTensor Coreは,FP6に対応はするものの,内部的にはFP8として処理するようで,FP8,FP6,INT8(8bit整数)の理論性能値が,同一となっている。FP6を使っても演算速度は速くならないので,使うメリットとしては,処理対象の学習データなどをFP8ベースよりもスリム化したいときのためといったところか。
なお,FP6へ対応するGPUは,2025年1月時点では少なく,GeForce RTX 50シリーズと,サーバー用GPU「GB100」「GB200」(関連記事)などの,Blackwell系GPUのみとなっている。
BlackwellのRT Coreは,交叉判定性能が2倍に
Blackwellにおいては,レイトレーシング機能にも数多くの改良が盛り込まれている。なるべく分かりやすくなるように説明してみよう。なお,レイトレーシングの基本については,以下の記事で説明しているので,理解を深めたい人は参照してほしい
関連記事
レイトレーシング処理の本質は,描画に必要な情報を集めるための3Dシーン構造体に対する探査にある。ライティングやシェーディングといったピクセルレベルの色を決める幾何学的,光学的な演算処理系は,昔ながらのプログラマブルシェーダユニットによる処理だ。
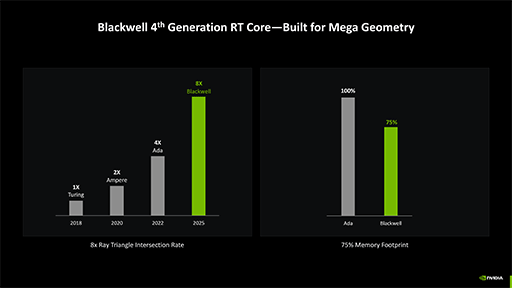
さて,Blackwellのレイトレーシングユニット「RT Core」は,第4世代に進化したそうで,レイトレーシング処理におけるポリゴンへの交叉判定性能は,2倍に向上したとNVIDIAは主張している。
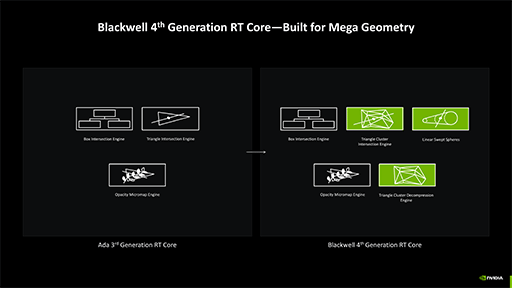 |
その一方でNVIDIAは,レイトレーシング向けの3Dシーン構造体「Bounding Volume Hierarchy」(以下,BVH)に対する探索効率については,「2倍に引き上げた」といった明確な説明をしていない。どうやら,「レイと衝突している可能性がある」として選んだBVHノードに対して,本当にレイとポリゴンが衝突していたかの判定速度を,Ada世代の2倍速に引き上げた,ということのようだ。
とはいえ,この性能強化は,既存のレイトレーシング対応ゲームの性能向上にも効くことは間違いない。
 |
Mega Geometryを理解するために必要なNaniteの仕組みを解説
BlackwellのRT Coreには,「Mega Geometry」機能と名付けられた新機能が実装された。NVIDIAは,Mega Geometryを実装した目的を説明するときに,「Unreal Engine 5」(以下,UE5)のジオメトリエンジン「Nanite」の解説から始めている。そこで本稿も,その流れに沿って話を進めていこう。
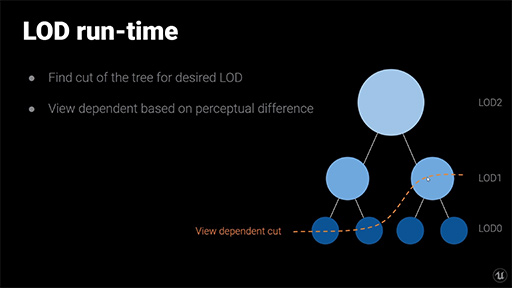
ゲームグラフィックスでは,視点からの距離の遠近に応じてジオメトリの詳細度を調整した3Dモデルを,必要に応じて適宜入れ替えて描画する「Level of Detail」(LOD)システムが使われている。視点(≒カメラ位置)から遠方にある3Dモデルは,画面上では小さく描かれるので,もともとポリゴン数の少ないモデルで描画する。逆に,視点から近い位置にある3Dモデルは,ポリゴン数の多い3Dモデルで描画する。これがLODシステムの基本的な理屈だ。
近距離用の最も精細でポリゴン数の多いモデルを,たとえば「LODレベル0」として,想定する視点からの距離に応じて,徐々に低ポリゴン化した3Dモデルを,「LODレベル1」「LODレベル2」といった具合に用意する。キャラクターや地形,建物や樹木なども同様だ。
一般的にLODシステムは,GPU側の機能ではなく,ゲームエンジンやグラフィックスエンジン側で実装する。たとえばPS3時代のゲームでは,近距離,中距離,遠距離の3段階LODを採用するものが多かった。また,PS4時代のオープンワールドRPGである「FINAL FANTASY XV」(以下,FFXV)では,メインキャラクターを,遠近に応じて10段階近いLODレベルで制御していた。
 |
プレイヤーがゲーム世界で移動していくと,グラフィックスエンジンは,視点からの遠近に応じて,各種3DオブジェクトのLODモデルを適宜入れ替えて描画する。その利点は,フレームレートの安定化や映像品質の最適化だ。
しかし問題点もある。LODレベルが切り替わる瞬間に,3Dモデルの形状,とくに輪郭が変化するので,3Dモデルを入れ替えたことがプレイヤーにバレることがある。これが「ポッピング」という現象だ。ゲーム好きならば,体験したことがあることだろう。10段階LODレベルを採用したFFXVでも,ポッピングを完全になくすことはできなかった。
 |
LODポッピングは,ゲームグラフィックスにおける永遠の課題であり,GPU側も,テッセレーションやメッシュシェーダーといった新技術で解決を模索してきたのだが,「これで解決!」というレベルには達していない。
そんな中,2020年にUnreal Engineの開発元であるEpic Gamesは,この課題に対するひとつの解として,動的な無段階LODシステムともいえるNaniteをUE5に実装すると発表したのだ。
 |
 |
厳密には,Naniteにおいても,従来のLOD制御のように,異なる詳細度の3Dモデルは用意してはおく。一般的には,最近距離,近距離,中距離,遠距離,最遠距離の4〜6段階くらいを用意するようだが,遠距離をあまり表示しないシーンでは,あえて近距離のみとか,近距離と中距離のみを用意するのもありのようだ。
Naniteでは,3Dモデルを構成するポリゴン群を「クラスタ」と呼ばれるグループで分ける。1つの3Dモデルは,複数のクラスタからなるわけだ。クラスタ分けのルールは,本稿では割愛するが,たとえば同じ材質で表現するものとか,3Dモデルの部位別などで分けるといったルールを用いるそうだ。
Naniteにおけるクラスタ分けとLOD生成は,UE5エディタや,Nanite支援ツール,Naniteのランタイム側で適宜行われる。そのため,これらのプロセスにおいては,開発者(プログラマーやデザイナー)の手作業は,基本的には必要ない。
 |
 |
クラスタ分けの結果,複数のLODレベルを有する3Dモデルが生成されていた場合は,それらすべてがクラスタの階層データに含まれることになる。具体的には,各LODレベルの3Dモデルを構成するポリゴンが,各クラスタごとに階層管理されるイメージだ。イメージ的にはテクスチャマップのMIP-MAPを連想すると分かりやすい。
各クラスタが管理するLODレベル1つあたり,128〜256ポリゴンで構成するのが一般的だそうだ。
 |
Naniteでは,クラスタ化した3Dモデルを3Dシーンに配置するわけだが,その3Dシーンのデータ構造には,BVHを採用している。正確には,3Dモデル単位でBVH化するのではなく,クラスタという単位でBVH化しているのだ。なぜNaniteがデータ構造にBVHを採用したのかは,後段で説明する。
ちなみに,Naniteによる3Dシーンの(クラスタ単位での)BVH化は,基本的にはUE5ツール上で行うもので,ゲームの実行中ではない。これが,現状のNaniteが静的な背景3Dシーン専用に限定されている理由のひとつだ。
Nanite管理下での3Dシーンの描画では,レイではなく視点からの距離に応じてBVHを探索して行き,視点からの画角範囲で描画対象クラスタを求めたり,視点からの距離に応じてLODレベルを選択したりする。
 |
なお,ポリゴンの集合体である各クラスタは,クラスタを代表する法線ベクトルを持っている。そのため,視線ベクトルと法線ベクトルによる角度が90度に近ければ,そのポリゴンが視点から見て輪郭付近であると判別できるわけだ。輪郭と判断した場合,一段,詳細度の高いLODに切り換えるといった制御も行う。というのもポッピングは,3Dモデルの輪郭が大きく変わった場合に起きやすいためだ。この制御でポッピング現象は大きく抑制できる。
3Dシーンの描画におけるBVH探索時には,遮蔽されているといった様々な理由によって描画する必要がないと確定したクラスタの破棄も行う。さらに,視線ベクトルと各クラスタの代表法線ベクトルの向きが同一方向に近い場合は,視線からは見えない面(背面)だと判断できるので,そのクラスタも描画対象から外される。
BVH探索を処理したあと,Naniteシステムは,描画することが確定したクラスタを描画していく。実際に描画するポリゴンは,選ばれたLODレベルのポリゴンになることは言うまでもない。
この描画時には,Nanite特有の処理が入る。それは,各クラスタのポリゴンを描画するときに,ポリゴンの大きさが描画解像度の1ピクセル以上か,1ピクセル未満かという判定だ。もし1ピクセル未満なら,ここでも描画する必要なしと判断できる。この処理こそが,Naniteの動的な無段階LODのリアルタイム実行に相当するのだ。その意味ではNaniteは,ある種のソフトウェアラスタライザの役割を持つと言えるかもしれない。
 |
GPUのテッセレーション機能を使わずに,リアルタイム動的LODシステムを実現するNaniteはこのような仕組みとなっていたのだ。以上が,Naniteのメカニクスとなるのだが,ここまで説明が分かりにくかったという人は,Epic Gamesが公開しているNaniteの技術解説動画も参考にしてほしい。
NaniteのBVH構造をレイトレーシングに応用したMega Geometry
ここからが,ようやく本題のMega Geometryの説明だ。
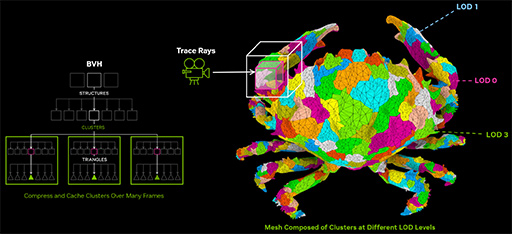
ある日,NVIDIAのエンジニアはこう考えた。「Naniteのジオメトリデータ構造にはBVHがあるので,レイトレーシングと親和性は高い。しかし,レイトレーシング用のBVHと比べると,クラスタとLODレベルという概念を追加している点が違いだ。もし,RT Coreが扱うBVHを,これら2つの概念に対応させれば,Nanite向けに構成した3Dシーンに対して,レイトレーシングを行えるのではないか?」と。
大胆な言い方をするなら,Nanite式のクラスタとLODレベルに対応したBVH構造体に対するレイトレーシングを可能にしたのがMega Geometry,といったところか。
 |
とはいえ,UE5のNaniteのBVHをそのまま(たとえばポインター経由で),Mega Geometryに渡すことはできない。BlackwellのMega Geometryを使って,Nanite式のBVHをレイトレーシングに使うには,Mega Geometry用のBVHを別途構築する必要はある。いうなれば,NaniteのBVHをMega Geometry向けにコンバートするといったところか。
NVIDIAは,Nanite式のクラスタとLODレベルの概念を導入したMega Geometry用のBVHを,「Cluster-level Acceleration Structures」(CLAS)と呼んでいる。
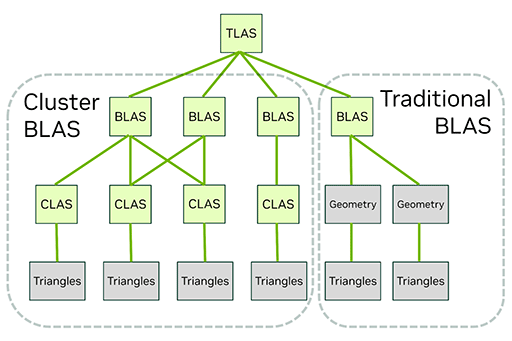 |
Mega Geometryは,あくまでもレイトレーシング支援機能なので,BVHコンバートでは,レイトレーシング処理系に都合の良い,Mega Geometryのために新設された新フォーマットのBVHに変換する必要がある。それが「Partitioned Top-Level Acceleration Structure」(PTLAS)だ。
レイトレーシングの基本的な概念記事でも説明しているが,近代レイトレーシングのBVHでは,大きな塊(下の図解で言うところのウサギ小屋に相当する)のBVHである「Top-level Acceleration Structure」(TLAS)と,3Dオブジェクト(3Dモデル)単位のBVHである「Bottom-Level Acceleration Structure」(BLAS)という,2段階で運用するのが一般的だ。
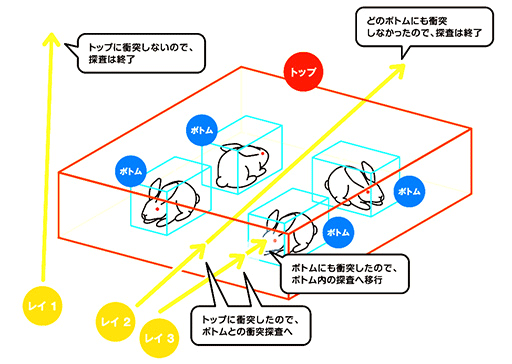 |
なお,別の個体であっても,同じ3Dオブジェクトを流用している場合,たとえば雑魚キャラや草木などは,同じBLASを流用してTLAS内に配置することもある(いわゆるインスタンシング)。
さて,BlackwellのPTLASは,従来は1つのみだったTLASを,ゲーム制作者の設計意図に合わせて,パーティション(Partitioned)分けしたTLAS(つまりPTLAS)として,複数個持てるように拡張したようなイメージだ。複数のPTLASをどう使い分けるかは,ゲームのジャンルやゲーム世界の管理形態に合わせて,ゲーム制作者が自由に行える。たとえば,広いエリアを探索できるタイプのゲームであれば,ゲームマップをいくつかのエリアに分けて,複数のPTLASを割り当てるといった使い方が考えられるだろう。
各PTLASは,主に背景オブジェクトのように静的な3Dオブジェクト群のみで構成されるものとし,基本的にゲームの進行中は,PTLASは更新しないものとして扱う。
しかしゲームでは,3Dオブジェクトが消えたり,新しい3Dオブジェクトが出現したりするので,そうした動的オブジェクト管理用のPTLASも必要だ。そこで,動的オブジェクトの管理用のPTLASとして「Global Partition」が持てるようになっている。
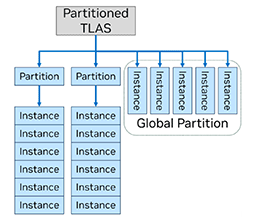 |
Ada世代以前のレイトレーシングでは,TLAS(のBVH)とBLAS(のBVH)からなるシンプルな2段階の構造で,静的3Dオブジェクトと動的3Dオブジェクトを統合して,単一のTLASで管理していた。静的3Dオブジェクトと動的3Dオブジェクトを分離して,2つのTLASで運用する場合もなくはなかったが,そうすると,2つのTLASに対してそれぞれレイトレーシングを処理しなければならない。
それがPTLASの仕組みでは,背景3Dオブジェクトで構成される任意のエリアのPTLASと,動的3Dオブジェクトで構成されるGlobal Partitionを,一度のレイトレーシングで処理できる。
また,ゲーム進行において,3Dオブジェクトの消失や出現があった場合,Ada世代以前のレイトレーシングでは,その都度,TLASやBLASの更新や再構築が必要だった。しかし,PTLASの仕組みであれば,動的3Dオブジェクト専用のGlobal Partitionだけを更新すれば済む。つまり,TLASやBLASの更新や再構築の機会をかなり節約して,最適化することにつながるのだ。
先述したとおり,Mega Geometryの開発の出発点は,「Naniteのジオメトリ構造をレイトレーシングで使えるようにしよう」だったはずだ。しかし,開発を進めて最適な機能設計を進めていくうちに,静的な背景3Dオブジェクトと動的な3Dオブジェクトそれぞれに対する,最適なレイトレーシング処理のためのBVH構造の改善を実現したようだ。
さらに,NVIDIAの開発者もMega Geometryの開発を振り返って,「ある事実に気付いてしまった」と述べている。
映画用CGや劇場CGアニメ作品におけるレイトレーシング描画のパイプラインは,こうなっていた。
- 少ポリゴンなベースモデルをアニメーションさせる
- 描画解像度に見合った詳細度でテッセレーションして,多ポリゴン化する
- 変移マップ(凹凸マップ)を元に,多ポリゴンモデルをディスプレースメントマッピングする
- レイトレーシングして描画する
NVIDIAは,「Mega Geometryによって,このパイプラインにおける2と3の部分を,『LOD付きCLAS構造体』に集約できることに気付いた」という。2のテッセレーションと3のディスプレースメントマッピングは,リアルタイムで行うので演算負荷がそれなりにかかる。一方,LOD付きCLAS構造体は,事前に計算しておけるので,速度面で圧倒的に有利となるのだ。
さすがに,ゲームに登場するすべての登場オブジェクトを,Mega Geometryでレイトレーシングする時代がすぐに訪れることはないだろう。しかし,「オールレイトレーシング」(オールパストレーシング)が大前提で,今でも複雑なシーンでは,1フレームを数十時間かけて描画することも多い映画向けCG制作シーンにおいては,Mega Geometryによるオールレイトレーシングは,レンダリングの劇的な時間短縮への糸口となるかもしれない。いずれは,プロ用レイトレーシングレンダラーが,Mega Geometryに最適化していくかもしれない。
Mega Geometryは,Blackwell専用であり,本稿執筆時点でフルサポートできるのは,NVIDIA謹製のレイトレーサーである「OptiX 9.0」が登場してからだ。ちなみに,本稿執筆時点での最新版は2024年10月リリースの「Optix 8.1.0」であり,Mega Geometryには対応しない。
また,DirectX RaytracingやVulkanといった標準APIからの利用もできない。つまり,ゲーム開発者がMega Geometryを利用したい場合は,各APIのNVIDIA製拡張API経由でしか使えないのだ。
一方で,NVIDIAによると,Mega Geometry自体については,GeForce RTXシリーズのすべてで利用できるよう,ドライバーレベルで互換性を取る方針であるという。しかし,いうまでもなくソフトウェア的な互換性維持になるので,ハードウェアレベルでMega Geometryに対応するBlackwellの第4世代RT Coreと比較すれば,性能的にはだいぶ落ちることになるようだ。
というのも,Blackwellでは,新しいBVHフォーマットであるPTLASを,グラフィックスメモリ上に圧縮した状態で保存しておき,これを直接アクセスできる。さらに,そもそもRT Coreの性能が高いのだ。また,PTLASを圧縮した状態のままで運用できるならば,グラフィックスメモリ消費量の削減という点でも有利になる。
|
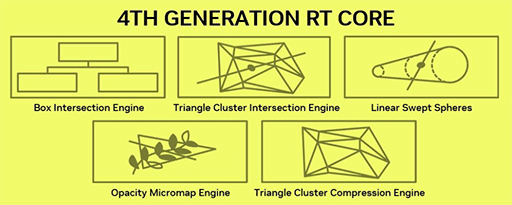 |
髪や細い草を表現するのに役立つ「Linear Swept Spheres」
レイトレーシングで扱うのが面倒なテーマに,毛髪や毛皮,葦(アシ)のように細長い草葉といった線分オブジェクトがある。最初からリアルタイム描画を考慮しない映画用CG制作の現場では,高次曲線プリミティブを使って線分オブジェクトを表現することもある。しかし,ゲームグラフィックスで,そんなことを試みる人はまれだ。
そのため,ゲームグラフィックスでは,線分オブジェクトは,複数のまっすぐな直線をつないだような,いわば「折れ線モデリング」で済ませる。そのうえでレイトレーシング時には,これを「十字ビルボード」※のようなポリゴンモデルである「Disjoint Orthogonal Triangle Strips」(DOTS)に置き換えて,BVH化することがある。
※2枚のビルボード(板型のポリゴン)が交差角90度で十字に交わったオブジェクト
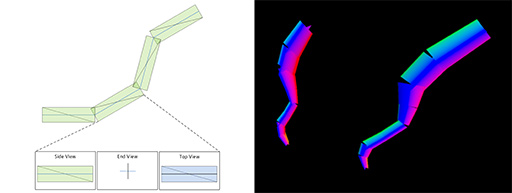 |
DOTSは,線と線の連結部が不連続となるため,視点に近い距離で描画するような折れ線オブジェクトが大きく描かれるときに,連結部分の不連続感が露呈して,不自然に見えてしまう。そこでNVIDIAは,Blackwellにおいて,リアルタイムレイトレーシングにおいても,折れ線オブジェクトをそれなりに自然かつ高品位に描画できるプリミティブとして,「Linear Swept Spheres」(LSS)という仕組みに対応したのだ。
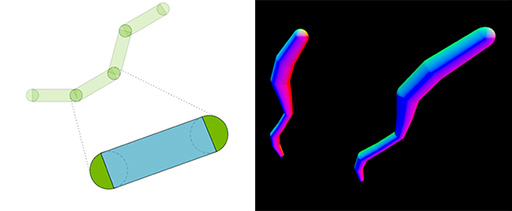 |
Linear Swept Spheresと聞くと難しく聞こえるが,長辺方向に長いカプセルがつながったような形状と言えば分かりやすいだろう。
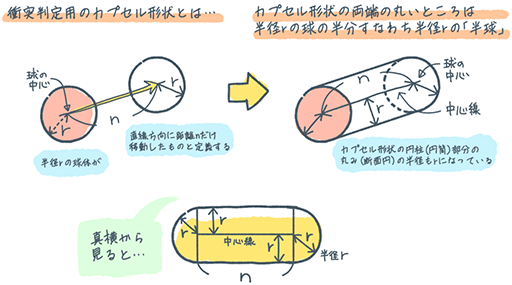 |
見た目は複雑そうなカプセル形状だが,実際はそうでもない。カプセル形状は,その形状を表すパラメータが,球体の半径「r」と移動距離「n」だけで済むので,他のプリミティブとの衝突判定の演算量が少なくて済む。そのため,演算負荷が少ないプリミティブとして人気なのである。それこそ,ゲーム向け物理シミュレーションなどにおいては,今でも採用率が高い。
さらにBlackwellのRT Coreは,ハードウェアレベルでカプセル連結モデルであるLSSとの交叉判定に対応していることから,処理速度も速いのだ。NVIDIAによると,折れ線モデルをLSSとして入力すれば,衝突判定がDOTSの2倍も速くなり,グラフィックスメモリの使用量も5分の1で済むとのことだ。
また,カプセル形状を構成する始点球の半径と終点球の半径を,それぞれ異なる値にした片側が小さいカプセル形状のプリミティブや移動距離nをゼロ=球形としたシンプルな球形プリミティブの入力にも対応している。
なかなか便利そうなLSSだが,Mega Geometryと異なり,カプセル形状プリミティブのLSSは,残念なことにBlackwell以降のRT Coreでしか対応できないとのことだ。
スペックでは見えない改良が多数盛り込まれたBlackwell
 |
今回は,GeForce RTX 50シリーズの全貌と,SMやTensor Coreの改良点,そしてメインディッシュのひとつであるレイトレーシング関連の話題まで扱った。
Blackwellが業界で初めて対応した新世代のプログラマブルシェーダアーキテクチャである「ニューラルレンダリング」や,メインメモリの「GDDR7」,ビデオエンコード/デコードに使うビデオプロセッサや,ゲームにおいて重要な超解像&フレーム生成技術「DLSS 4」については,後編で取り上げたい。
NVIDIAのGeForce RTX 50シリーズ製品情報
- 関連タイトル:
 GeForce RTX 50
GeForce RTX 50 - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー